Architecture Overview¶
Modern virtual assistants such as Amazon Alexa and Google assistants integrate and orchestrate different conversational skills to address a wide spectrum of user’s tasks. DeepPavlov Agent is a framework for development of scalable and production ready multi-skill virtual assistants, complex dialogue systems and chatbots.
Key features:
- scalability and reliability in highload environment due to micro-service architecture
- ease of adding and orchestrating conversational skills
- shared memory of dialog state and NLP annotations accessible to all skills
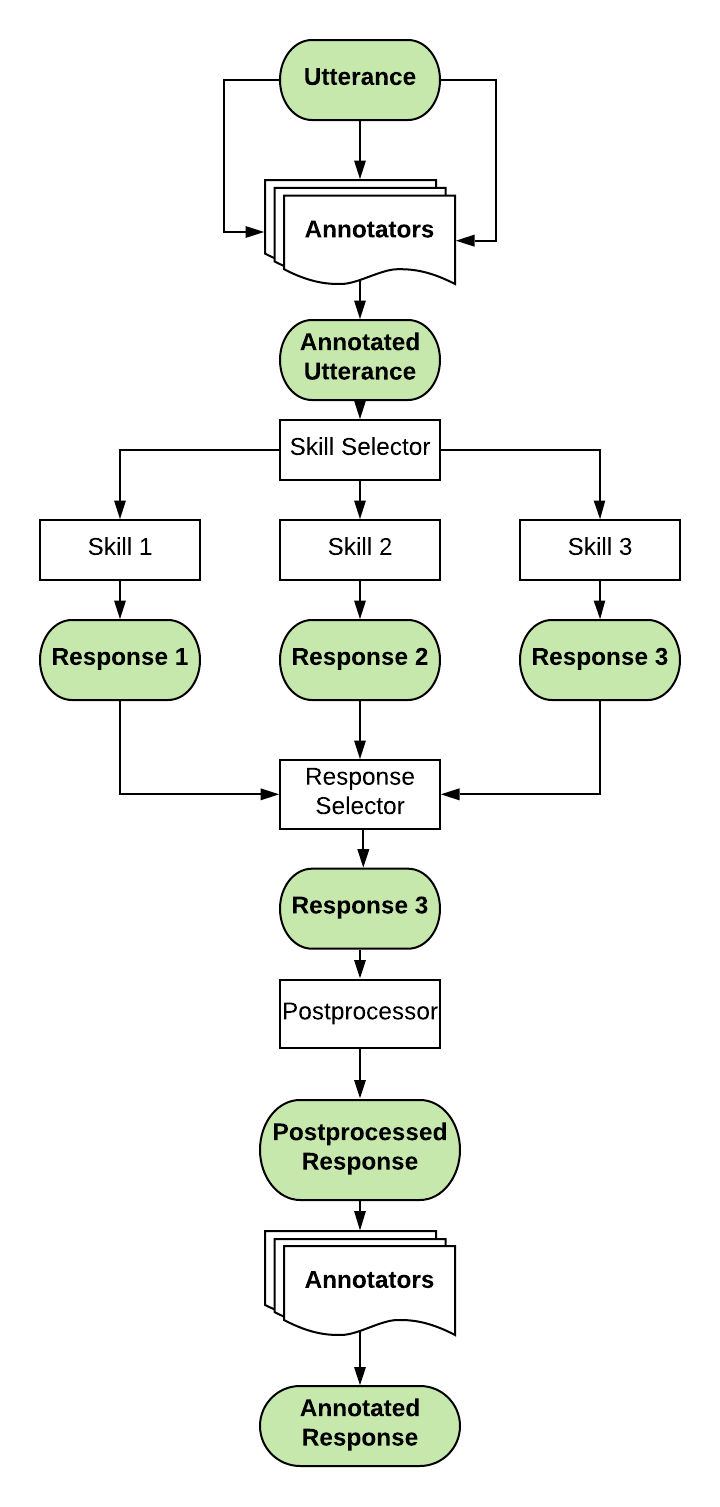
Core concepts of DeepPavlov Agent architecture:
Utteranceis a single message produced by a human or a bot;Serviceis a NLP model or any other external service that supports a REST API.DeepPavlov Agent orchestrates following types of services:
Annotatoris a service for NLP preprocessing of an utterance. It can implement some basic text processing like spell correction, named entity recognition, etc.;Skillis a service producing a conversational response for a current dialogue state;Skill Selectoris a service that selects a subset of available skills for producing candidate responses;Response Selectoris a service selecting out of available candidates a response to be sent to the user;Postprocessoris a service postprocessing a response utterance. It can make some basic things like adding a user name, inserting emojis, etc.
Postprocessed Responseis a final postprocessed conversational agent utterance that is shown to the user.Statestores current dialogs between users and a conversational agent as well as other infromation serialized in a json format. State is used to share information across the services and stores all required information about the current dialogs. Dialogue state is documented here.
Installation¶
Deeppavlov agent requires python >= 3.7 and can be installed from pip.
pip install deeppavlov_agent
Running the Agent¶
Agent can be run inside a container or on a local machine. The default Agent port is 4242. To launch the agent enter:
python -m deeppavlov_agent.run_http
Command parameters are set via deepavlov_agent/settings.yaml:
- -ch - output channel for agent. Could be either
http_clientorcmd_client- -p - port for http_client, default value is 4242
- -pl - pipeline config path, you can use multiple pipeline configs at the time, next one will update previous
- -d - database config path
- -rl - include response logger
- -d - launch in debug mode (additional data in http output)
The agent can send information about exceptions to Sentry using setted environment variable DP_AGENT_SENTRY_DSN.
HTTP api server¶
Web server accepts POST requests with application/json content-type
Request should be in form:
{ "user_id": "unique id of user", "payload": "phrase, which should be processed by agent" }
Example of running request with curl:
curl --header "Content-Type: application/json" \ --request POST \ --data '{"user_id":"xyz","payload":"hello"}' \ http://localhost:4242
Agent returns a json response:
{ "user_id": "same user id as in request", "response": "phrase, which were generated by skills in order to respond" }
In case of wrong format, HTTP errors will be returned.
Arbitrary input format of the Agent Server
If you want to send anything to the Agent, except
user_idandpayload, just pass it as an additional key-value item, for example:curl --header "Content-Type: application/json" \ --request POST \ --data '{"user_id":"xyz","payload":"hello", "my_custom_dialog_id": 111}' \ http://localhost:4242
All additional items will be stored in the Agents
stateinto theattributesfield of aHumanUtterance. Dialogue state is documented hereRetrieve dialogs from the database through GET requests
Dialogs’ history is returned in json format which can be easily prettifyed with various browser extensions.
Logs can be accessed at (examples are shown for the case when the agent is running on http://localhost:4242):
- http://localhost:4242/api/dialogs/<dialog_id> - provides exact dialog
- http://localhost:4242/api/user/<user_id> - provides all dialogs by user_id
Load analytics
Number of processing tasks and average response time for both the agent and separate services are provided in a real time on the page http://localhost:4242/debug/current_load .
Analyzing the data¶
History of the agent’s state for all dialogues is stored to a Mongo DB. The state includes utterences from user with corresponding responses. It also includes all the additional data generated by agent’s services.
Following Mongo collections can be dumped separately:
- Human
- Bot
- User (Human & Bot)
- HumanUtterance
- BotUtterance
- Utterance (HumanUtterance & BotUtterance)
- Dialog